Nel corso degli anni sono state sviluppate due tecnologie per il supporto allâesecuzione di più threads in contemporanea:
-
SMT (Simultaneous Multi Threading): Forza lâesecuzione di due threads in un solo core sfruttando il non completo utilizzo di tutte le risorse disponibili. Ogni threads deve âcombattereâ per ottenere le risorse di cui ha bisogno ed eventualmente attendere lâesecuzione dellâaltro thread per proseguire.
-
CMP (Chip Level Multiprocessing): Ogni thread ha un core dedicato, è un approccio di forza bruta, rispetto al SMT, la condivisione di risorse è a livello più alto e, in caso di numerose risorse condivise, un intero core può restare in attesa della terminazione degli altri processi causando un grande sottoutilizzo del sistema.

SMT è stato il primo approccio al multi threading ed ha portato a notevoli incrementi prestazionali riuscendo a recuperare i tempi morti (es. caricamento dei dati dalla memoria) e sfruttarli per lâesecuzione di altre operazioni: lâincremento di un 10% dellâelettronica può portare ad incrementi delle prestazioni fino al 50% contrariamente al raddoppio della circuiteria necessaria per un approccio CMP su due core.

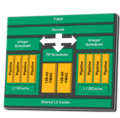
AMD ha scelto un approccio ibrido, includendo in ogni modulo Bulldozer due core, ma condividendo tra i due alcune unità di elaborazione e tutta la logica di gestione e controllo. Questo approccio porta ad una drastica riduzione del numero di circuiti necessari per un approccio CMP, senza però aver gli svantaggi della schedulazione introdotta dal SMT. I componenti condivisi in Bulldozer sono i circuiti dedicati al Fetch e Decodifica delle istruzioni che sono stati migliorati ed ampliati rispetto al passato, passando da un decoder a 4 vie in grado di fondere branch di istruzioni x86 e aumentare così lâefficienza complessiva; un simile approccio è già stato proposto da Intel nelle CPU Nehalem.

Un altro componente condiviso tra i due âcoreâ è lâunità per lâelaborazione Floating Point: AMD ha infatti messo in evidenza, come circa 80% delle elaborazioni comuni siano basate solo su interi ed ha quindi deciso questo taglio rispetto al passato. Seppur vero che in ambito consumer e lavorativo la maggior parte dellâelaborazione riguarda proprio gli interi, in ambito High Performance Computing e Server, si ha sempre una maggior richiesta di potenza di calcolo in Floating Point, basti ricordare che NVIDIA ha dovuto modificare la sua GPU G80 al fine di supportare completamente le specifiche per il calcolo a doppia precisione richieste per lâelaborazione con la tecnologia CUDA in ambito scientifico. AMD ha comunque una risposta a questa obiezione citando le nascenti tecnologie di calcolo parallelo basate sulle GPU e lâintroduzione di OpenCL, linguaggio da sempre sostenuto dalla casa di Sunnyvale e supportato dalle schede video Radeon e FireGL.
Solo con il lancio effettivo sul mercato di queste soluzioni, potremmo dare un giudizio su questa scelta progettuale.

La pipeline di Bulldozer è stata allungata e questo ha reso necessario lâintroduzione di tecniche di prefetch più evolute al fine evitare interruzioni durante lâesecuzione delle istruzioni; collo di bottiglia di questa scelta è il controller di memoria, su cui però non sono ancora stati alzati i veli, lasciando trapelare solo indiscrezioni su una versione ottimizzata dell'attuale controller DDR3. à presumibile che sarà mantenuto un approccio ad un controller a due canali per il mercato consumer e fino a quattro per la versione server.
Ogni unità di elaborazione (2 integer e 1 floating point) è dotata di uno scheduler dedicato e per quanto riguarda le unità intere di una cache di primo livello da 16k e di una unità DTLB a 32 vie associativa.
La cache di secondo livello è unificata a livello di modulo Bulldozer ed è condivisa per le tre unità di elaborazione incluse.





